From Code Centric to Data Centric
Your data is your most valuable asset; would you leave the knowledge of your data into the code of a developer who sooner or later is going to leave?
Some Definitions
Data Centric refers to an architecture where data is the primary and permanent asset, and applications come and go. In the data centric architecture, the data model precedes the implementation of any specific application and will be there and valid long after it is gone.
Therefore, with a Code Centric architecture the semantics of data are embedded and residing in the code of the applications, while with a Data Centric architecture the semantics of data are managed as a key asset together with data, independently from the code of the applications.
An Historical Perspective
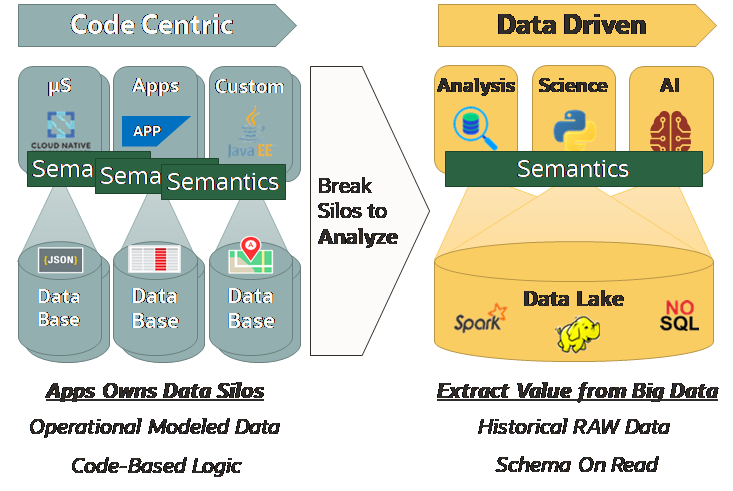
Many years ago, we faced the same issue. Developers used to write Cobol procedures coding also the semantics of data, using a kind of key-value data store named VSAM on mainframe, but companies lost the control of this logic, when developers left the company or just changed the role.
Relational Databases have been a first attempt to move semantics from code to data, allowing many people and many procedures to work on the same data model. Unfortunately, different applications continued to have different data models, building silos that were preventing a holistic view of data. So, we actually moved from a Code Centric approach to a siloed Application Centric architecture.
As a result companies built Data Warehouses, but every time they needed to load new data, new code had to be developed to extract data from applications, not only slowing down the process, but also losing the control of this code as soon as developers left the company or just retired.
Data Lake doesn’t mean Data-Centric
More recently companies tried a different approach, building Data Lakes where all data from all applications was supposed to be loaded as “raw data” and used with “schema on read”. However new code had to be developed for interpreting and transforming the raw data, moving back the semantics from data to code.
Moreover, Data Lakes are supposed to “extract value from data”, but if this value is not applied back to the applications, it doesn’t have a big impact on the business. This value, like a statistical model trained with machine learning, must be applied to the real time data of business-critical applications.
This is why most of the companies are complaining that the business impact of Data Lakes is less than expected. Developing a change on the code of a business-critical application can be very difficult and slow if not impossible, and the access to real time data can be very difficult as well.
I don’t want to be misunderstood, companies can benefit by building a Data Lake using tools, skills and culture that will allow them to make better decisions. However, for fully exploiting the value extracted from data, companies must evolve the Data Driven organization to be more Data Centric.
How to build a Data Platform for a Data Centric company?
For becoming Data Centric a company must build a Data Platform containing all data and semantics, not only for “understanding” the data, but also for “doing” with all data.
This basically means that the Data Platform must:
1. be able to handle every kind of data and semantics;
2. allow not only to query but also to update data in real time;
3. be decoupled from applications through a logical interface;
4. be highly secure, available and scalable keeping the consistency.
Being able to handle every kind of data and semantics, means at least to be able to manage every data type and data model, including Relational, JSON, XML, Graph, Spatial, OLAP… allowing to correlate data across different data models for being able to answer questions like “find all customers living in less than X miles from my shops, providing a turnover higher than Y $ and with the attribute Z” where X is Spatial, Y is Relational and Z is JSON.
But data semantics can be more than just data types and data models. The Data Platform should have also a Data Catalog with all metadata providing both technical and functional description of data, as well as rules and mechanisms for enforcing data consistency, security and access logic.
Being able to allow not only to query but also to update data in real time, means that data is not supposed to be just queried but also continuously updated in real time by the applications. Running a query while data is changing in real time is quite tricky since the query could return wrong results, for example a query on a changing customer address could return the new city and the old street.
Therefore, the Transactional Consistency is a key feature of a data platform managing real time continuous changing data. Eventual consistency is not acceptable. Moreover, the consistency must be implemented ensuring scalability and parallel access to data from many applications.
Being decoupled from applications through a logical interface, means that applications can access the data platform only through a well-defined logical interface supporting various ways of access like REST APIs, SQL access, Event streaming etc. The aim of providing a logical interface to all applications is also to decouple applications from data, keeping the logic in the code separated from the logic in the data, thus allowing to evolve independently both the applications and the data platform.
Finally, as the architecture is so Data Centric, it is obvious that the Data Platform must be highly secure, available and scalable keeping the consistency. Highly secure for protecting the data, the most valuable asset, not only from data loss, but also from data corruptions as well as from anomalous data usage. Continuously available, since applications are relying on the data platform not just for analytic purposes but for the business continuity.
The data platform must be able to scale-out indefinitely, in order to avoid becoming the bottleneck of the company, but keeping at the transactional consistency for managing real time changing data without wrong results, also with transactions and queries involving different data types and models.

How can a company become Data-Centric?
Becoming Data Centric is not a one-off activity. It is a long journey, and a continuous process.
Also because enterprise companies cannot re-build everything from scratch like startups. Most of the business is running on current business critical systems, sometimes also called “legacy” systems, while new modern digital applications are being developed, aiming to be more “agile” and “innovative” leveraging both SaaS and Cloud Native technologies.

I’m used to call this the “dual challenge” of enterprise companies. On the left side, companies must improve efficiency and business continuity also reducing costs and risks. On the right side, they should innovate by developing new applications also to “apply the value” that has been “extracted from data”, often from a data lake that usually represented the first attempt of innovation.
But companies realized very soon that new modern digital applications on the right need data coming from the current business critical systems on the left, and very often this data must be provided in real time. The first simplistic way to do it has been allowing the new digital applications on the right to consume services exposed from the left, but legacy business critical systems are not suitable to handle the unpredictable peaks of workload coming from new digital applications.
This is why companies started to build on the right a new data platform, for keeping a near real time copy of the production data in order to protect the current business-critical systems from the unpredictable workloads coming from new modern digital applications.

Building the new data platform for the new digital applications is the best opportunity to become more Data Centric!
Indeed, the data platform must be “able to handle every kind of data and semantics”, in order to manage both data coming from current mission critical systems and data of new digital applications; and must “allow not only to query but also to update data in real time”, to manage in a consistent way both data coming in real time from mission critical systems and data updated in real time by new digital applications. As a result, this data platform needs most of the Data Centric capabilities.
Companies should also keep this data platform “decoupled from applications through a logical interface”, to avoid that data semantics would be embedded on the code of some applications, thus not allowing to share the same data with different applications. And obviously the data platform should be also “highly secure, available and scalable keeping the consistency”, being so critical.
Therefore, the best way for a company to become more and more Data Centric is to build a data platform following all the principles for Data Centricity, and then to gradually develop on top of it all future new modern digital applications.
Trying to summarize
In the past we already moved many times back and forth from Code Centricity to Data Centricity and vice versa, since both approaches have pros and cons, but with the increasing aim of companies to leverage all data as a valuable and strategic asset not just for taking decisions but also for improving and innovating the business, Data Centricity is getting more and more traction.
